Transformer Architecture
Jul 18, 2024
machine-learning
This is a Neural Network architecture which originates from the paper “Attention Is All You Need”. It’s primarily use is for text based models, but can also be modified to be used for other data sources, e.g. image purposes (Vision Transformer).
The transformer model can learn which words are important to a given sentence (as well as how words relate to one another), using the attention mechanism. Unlike previous NLP models, it can have an infinitely long context window (within the provided input limit).
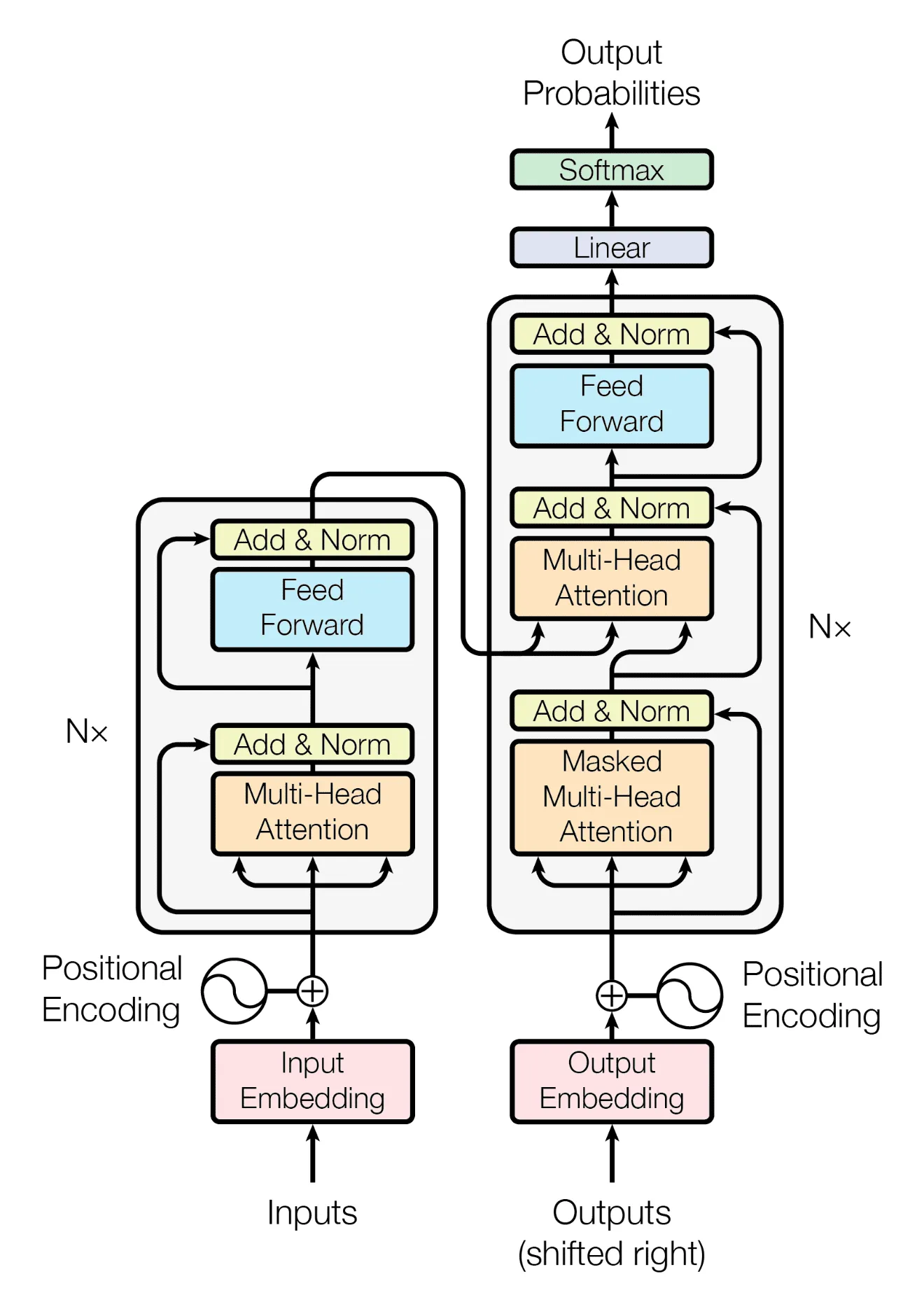
It consists of 2 main components – the Encoder (left) and the Decoder (right). Both of them are provided with a text input which is tokenized and then represented as a Vector Embedding. One of the goals is optimizing the encoder and decoder, such that we get the best representation of our inputs. This is known as pre-training. After we’ve pretrained the encoder and decoder, we can change the head at the end and fine-tune our model for different purposes.
The Encoder’s purpose is to encode the meaning of the input (the vector embedding), the positions of the words themselves (Positional Encoding), as well as how words relate to one another (Multi-Head Attention).
The Decoder’s purpose is exactly the same, but for the output input. The masked multi-head attention head prevents the model from “cheating” by looking ahead in the output input - it assigns to the values above the main diagonal. This will make the model causal - it only depends on previous states.

The encoder’s output is connected to the decoder’s second multi-head attention layer - acting as the Key and Value inputs. We combine that with the output of the previous masked multi-head attention layer to act as the Query input.
In between all the layers, you can find Layer Normalization layers to normalize the values.
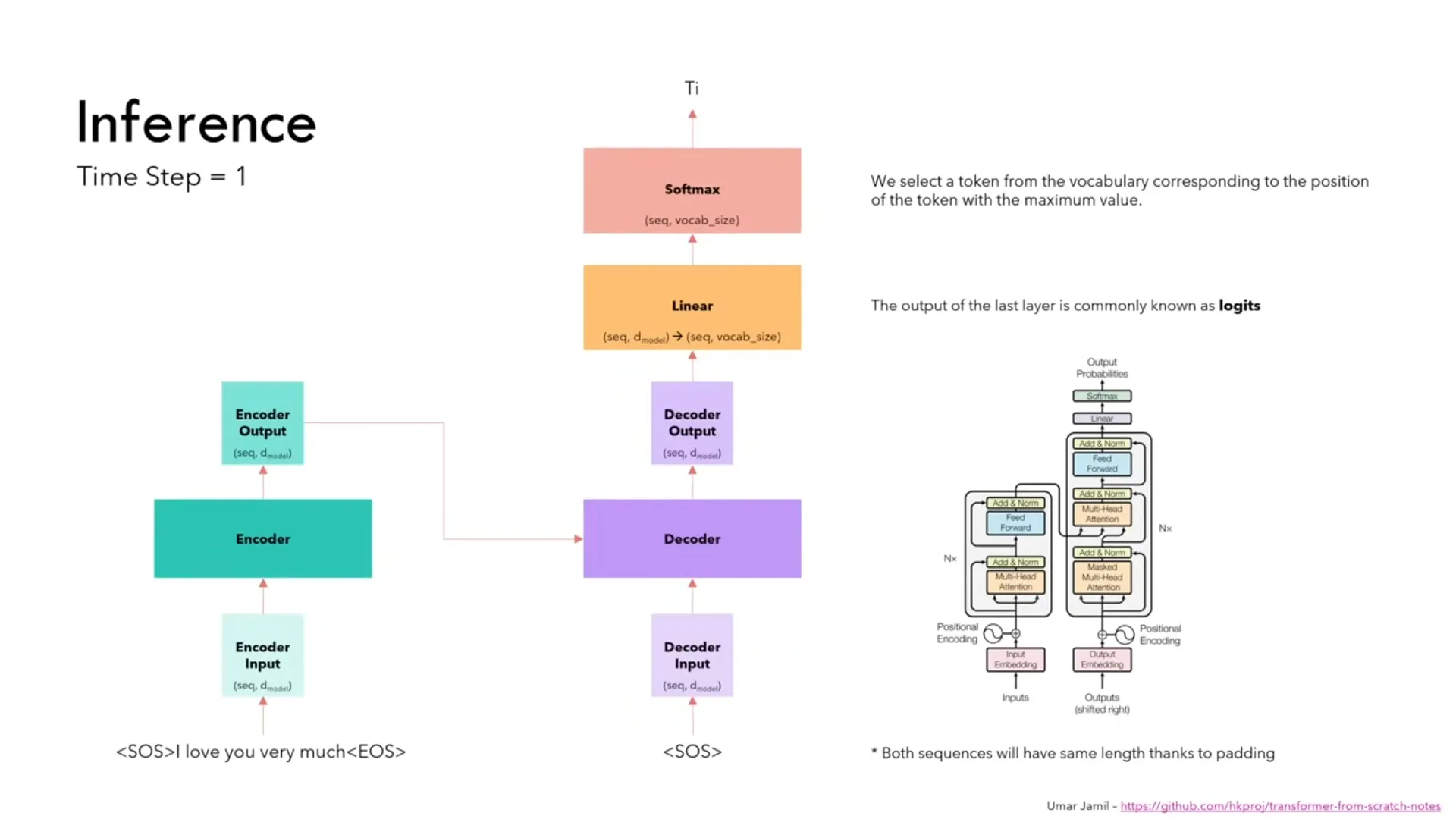
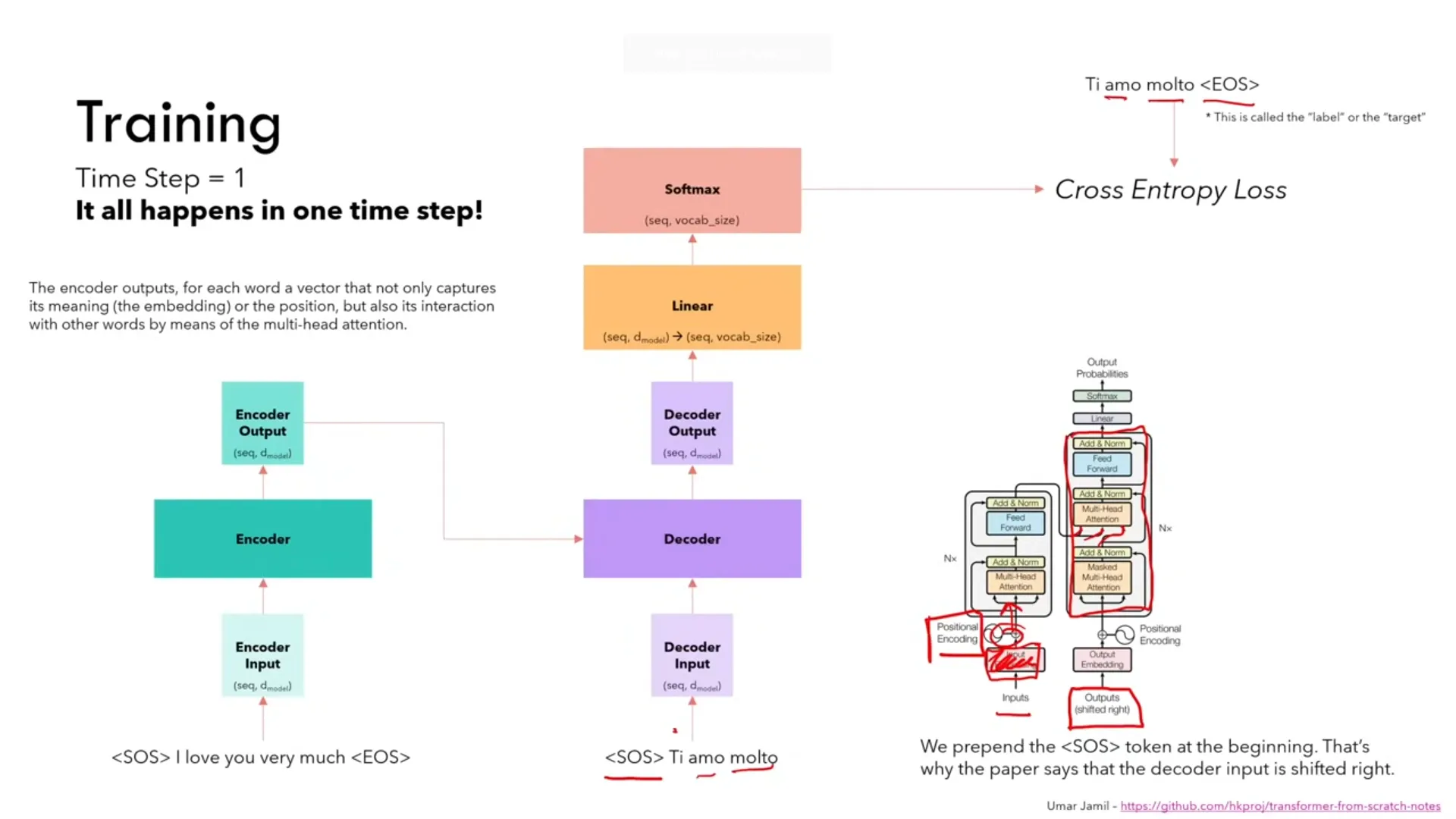
During training, the input and output embeddings represent the input and the expected output. You surround the inputs with special tokens to indicate the beginning / end of sentences. The model outputs all of the next tokens in 1 time step. There’s no for loop or iteration required for the model to give an answer.
During inference, the input is the also surrounded with special tokens, but the output input is only a token which indicates the beginning of a sentence. This will spit out a single token and you have to keep feeding the output of the model to the output input. You repeat this until you reach a special end of sentence token.