Vector Embedding
Jul 18, 2024
machine-learning
You can represent any kind of data as an N-dimensional vector. For example you can use it for representing words when doing natural language processing. You do to this by assigning a random vector to each word in your input. You then train some kind of model, such that it begins grouping related words closer together and opposite words further from each other. The dimensionality of the vector is completely arbitrary and it’s up to you to decide. You would hope that the different parts of the vector represent or learn different aspects of the word – but you can’t really know what the numbers mean for sure as it’s all a black box.
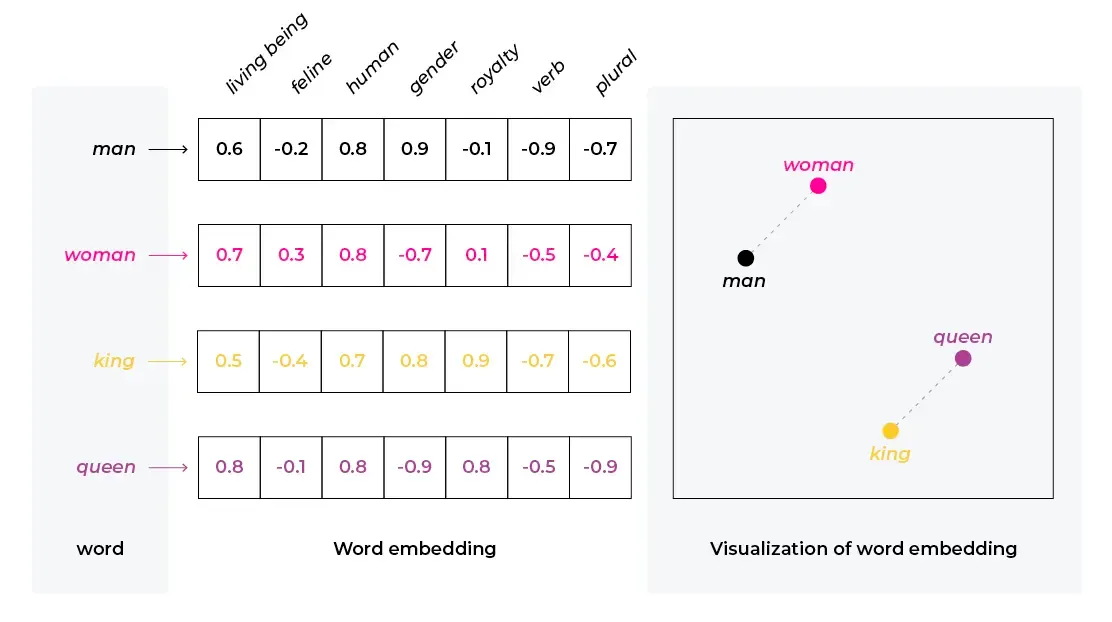
These vectors can be used to perform different mathematical operations. For example, if you take the vector for “King”, subtract the vector for “Man”, add the vector for “Woman”, you would get a vector that’s very close to the vector for “Queen”. The same idea can be applied to other form of data, for example images.