Perceptron
Jul 18, 2024
machine-learning
The perceptron is a basic mathematical model for solving Binary Classification problems. It consists of 2 components:
- Weights & Biases
- You can think of these as knobs that you tweak to get the desired result
- They are just numbers
- The difference between both arises in the learning process
It’s quite limited and can’t solve anything that isn’t linearly separable, for example the XOR problem.
Example
Let’s solve a classic problem, determining whether a point lies below or above a line
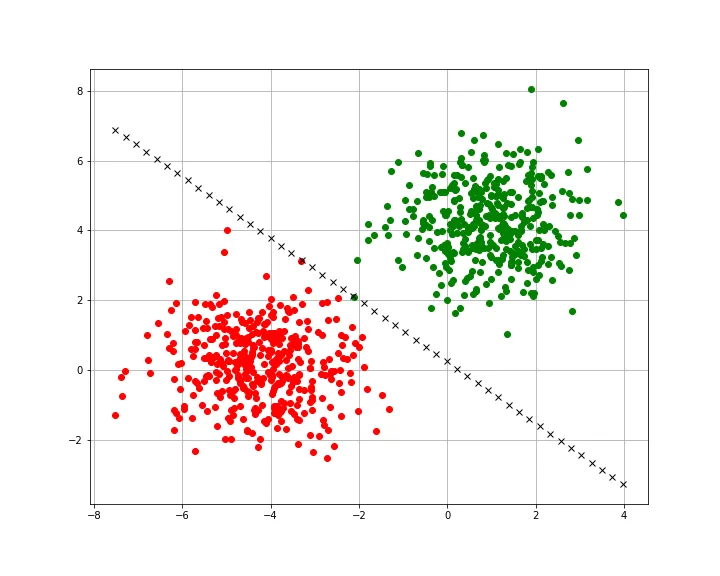
- The input of our perceptron will be the X and Y coordinates of the point.
- The output of our perceptron should be a number, let’s say that means that it’s below the line and , above the line.
Prediction
The feed forward (or in other words, the “prediction”) process involves several steps
- Provide some sort of input, and
- Compute the weighted sum of the respective weights,
- Add the bias,
- Plug the result into an activation function
- The output will determine whether the point lies below or above the line
- The above steps can be summarized as
- At first, our perceptron will perform very poorly. This is because usually the weights are completely random.
Learning
We can use a simplified version of Supervised Learning to optimize our model.
We can compute the error for our model - . We can then update our weights - where is our Learning Rate and is our input. We can then also update our bias - .
We repeat this process a bunch of times, until our model converges.
An example implementation can be found on my GitHub repo