Neural Network Architecture
Jul 18, 2024
machine-learning
A Neural Network consists of many “neurons”, which are simply numbers. You can think of them as neurons from biology - they can be activated or not.
These neurons build up layers. The first layer is your input, e.g if we take the problem of classifying images, you would take in an array of all the pixel values.
These neurons are connected using weights and biases. These are the parameters of the neural network. Just like the neurons, they are also just numbers. The end goal of training a neural network is to find the parameters that best solve your problem.
Each neuron from the previous layer is connected to every neuron in the next layer. Generally you need more layers in order to solve more complicated tasks. The term deep learning comes from literally having a deep neural network, i.e using many layers. Having more layers and thus, more parameters, makes the learning process more computationally expensive. There are many different types of layers, each tailored to solving specific problems.
At the end of each layer, you configure an Activation Function. At the last layer, you configure a Cost Function and an Optimizer.
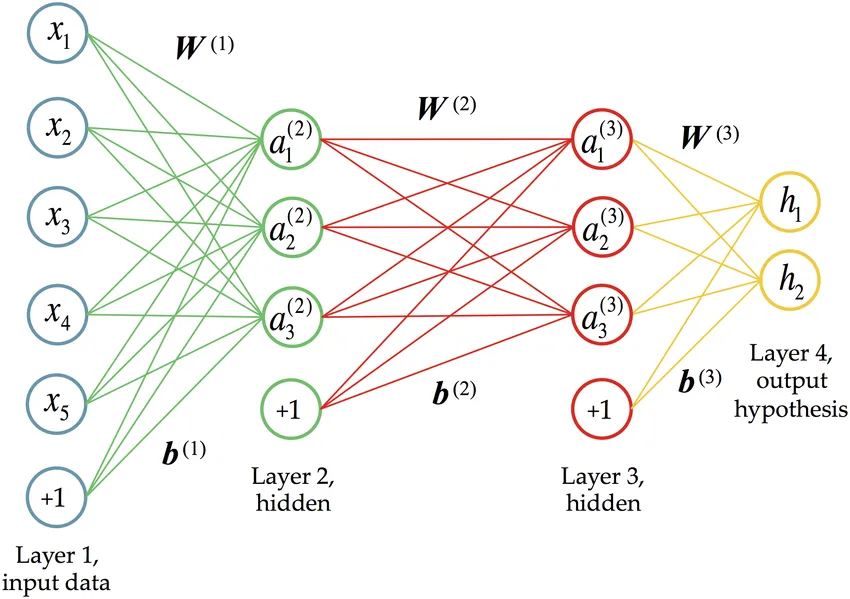
It is commonly represented using matrices (or the more general term, tensors). GPUs are optimized to compute many matrix operations in parallel, such as matrix multiplication (which is the core operation in neural networks), which is why they are used for training and running neural networks.
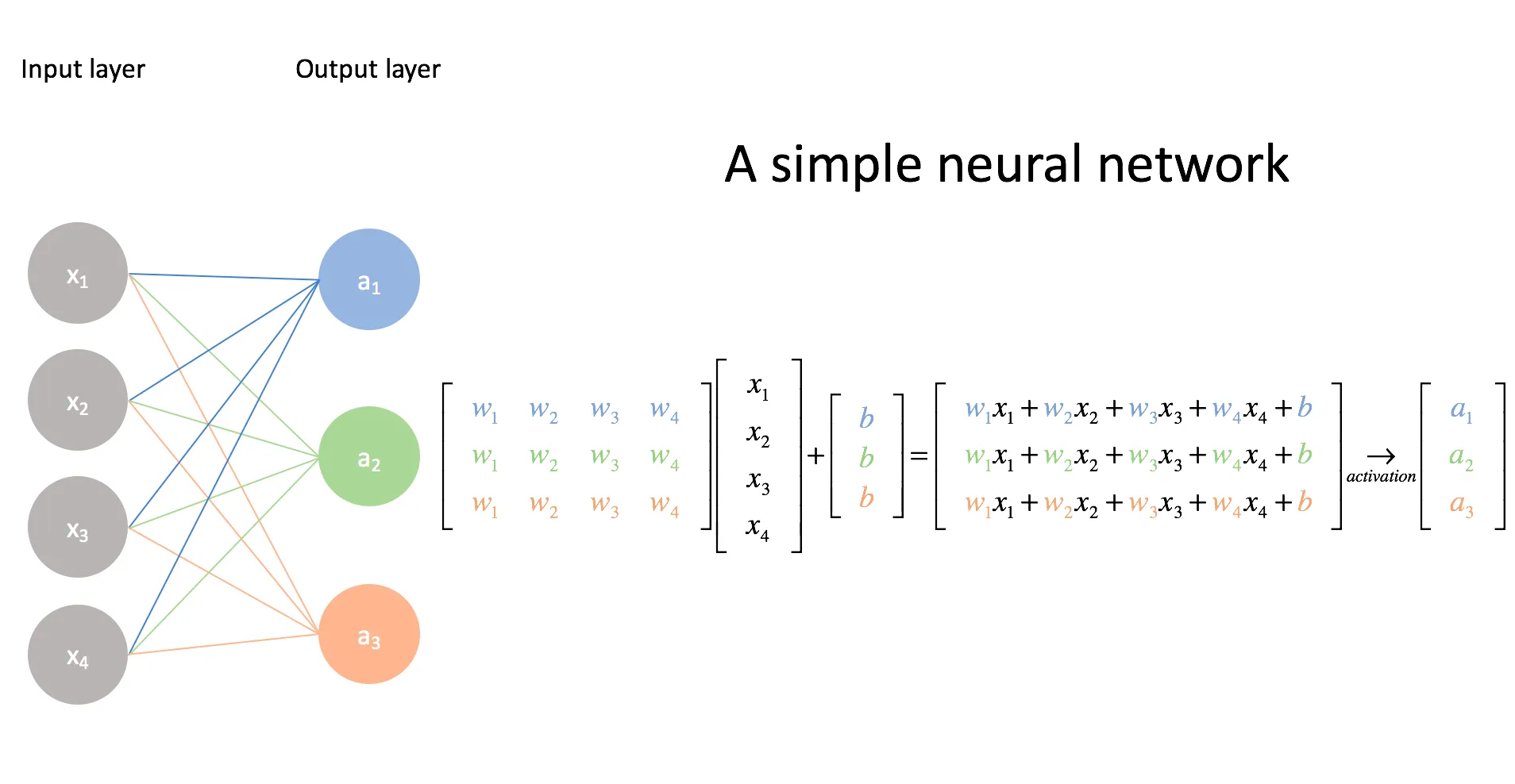
Here we can see that the weights from the input layer that connect to neuron in the output layer, are all in the row of the weight matrix.